Democratizing the Exciting New Wave of AI

Imagine if you could have something similar to the genie from Aladdin. This powerful apparition could grant you any wish without limit. All you have to do is make a request, and he works his magic to make it come true.
The latest AI generative models do feel like they came out of a magical lamp; you enter a prompt describing what you want, and shortly after, a creative image representing the request appears; you ask it to write an essay about a given topic, and a series of paragraphs show up in seconds. This development is made up of diffusion models and large language models (LLMs), which have led to some impressive advances in AI.
This post is divided into two parts. The first one covers an overview of the recent progressions in AI, the possibilities they open, and their challenges. The second part explores a few thoughts on how to democratize access for all and avoid excess control by a handful of large organizations.
If you are already familiar with the space, you can skip to Part II.
Part I- The Potential of Language Models: Examining the Benefits and Challenges
The evolution of AI has been extremely slow from the field's inception in the mid-fifties until the late nineties. However, about a decade ago, the implementation of Deep Learning, enabled by cloud computing and the availability of large data sets, led to revolutions in areas such as computer vision, speech recognition, autonomous driving, forecasting, and fraud detection. A tipping point was reached where exponential improvements seemed possible.
Nonetheless, after a few years of excitement, Deep Learning applications appeared to perform well on domains such as the ones mentioned above but couldn't effectively solve natural language processing (NLP). A short interaction with a customer support virtual assistant should suffice to convince you that the service was close to unusable and was among the most frustrating user experiences. Even personal assistants like Siri and Alexa can only handle a predefined set of questions.
But the arrival of the Transformer Neural Networks Architecture in 2017 marked a new turning point that leaped forward the natural language processing field, in a few years, and gave birth to a new generation of models such as ChatGPT, the latest implementation by OpenAI. Those new models outperformed the previous architectures on a range of NLP tasks and can answer any question, write articles, fiction stories and software code with mind-boggling realism. For the first time, we witnessed a language fluency closer to what was imagined in sci-fi with HAL 9000 from the movie 2001: A Space Odyssey.
It is not hard to see that the effects on society and the future of work are profound. Still, we may not fully realize all of the ways natural language processing will change our world in the long run. What we can do, at the moment, is to try to anticipate some of the short and mid-term outcomes.
The Good
The immediate benefits will come from leveraging LLMs as sidekicks for humans to expand their creativity, speed up their workflows and grow their earning capacity rather than threatening their jobs.
Several great applications have already emerged. For example, GitHub Copilot helps software developers quickly generate code; LEX assists authors in alleviating writer's block and coming up with more ideas; resumeworded.com provides personalized feedback on resumes and LinkedIn profiles, helping increase job opportunities; open-source visual models such as Stable Diffusion have been customized and repurposed for specific use cases. For example:
Profilepicture.ai uses a set of your photos to automatically produce creative profile portraits with various styles suitable for different occasions.
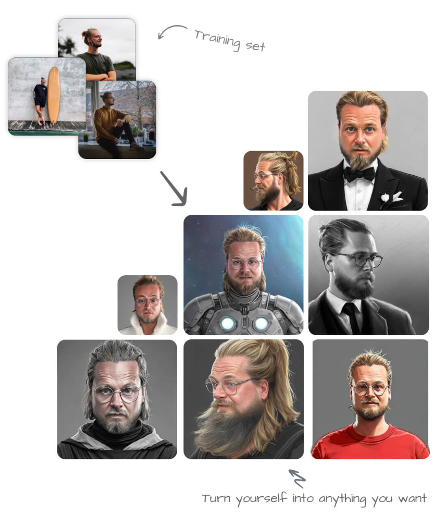
InteriorAI.com lets you upload a snap of your interior and provides a remodeled version of the room based on specific styles. Looking at the examples, it seems the system works by doing an image search for similar spaces in the selected style rather than generating new designs from diffusion. Still, the results are pretty cool.


But it doesn’t stop there. LLMs can also:
Create digests of long articles or books
The functionality saves time and is an invaluable tool for people with disabilities who have difficulty reading or processing large amounts of information.
Askmybook.com by Sahil Lavingia is an interesting experimental idea where you can ask questions about the content of his book.
Built something new! An experiment in using AI to make my book’s content more accessible.
— Sahil Lavingia (@shl) November 15, 2022
You can use Ask My Book to ask a question and get an answer in my voice.
Try it out: https://t.co/oyo9aPfBv1 pic.twitter.com/JQXdIZJ92n
Generate structured legal documents
“Write a standard lease agreement for an apartment.”
👇

The outcome's quality is rock solid, providing accessibility to anyone at a low cost.
Write songs and poems
“Write a song about the state of the world today and make it rhyme.”
👇

While it's far from perfect, it's a pretty stunning base, generated in a few seconds, that an artist could start from to craft the lyrics of a complete song.
Evaluate business ideas
“Is it a good idea to create a competitor to twitter?”
👇

“Why did Elon Musk buy twitter?”
👇

Those answers are as good as what a generalist person, not deeply involved in the matter, would provide.
Do a few more things
The LLMs’ possibilities go even further. The thread below contains more examples from the latest OpenAI release.
All the best examples of ChatGPT, from OpenAI:
— Ben Tossell (@bentossell) December 1, 2022
Beyond what’s already possible, what other skills could those models learn in the future?
For example, they could be trained on the entire collection of business plans, financial models, and strategic narratives contained in PowerPoint decks and Excel files from management consulting firms. The models would then allow anyone to generate business presentations and spreadsheets in seconds that could later be manually edited. The gains in productivity would be huge. Such a service may also open up alternative business models for consulting companies with software subscriptions for a new kind of offerings that could be named "Copilot for Slides" and "Copilot for Excel Models."
Another area with good potential is psychotherapy. If the models are trained on transcripts and recorded audio of sessions provided by practitioners, they could enable the creation of an affordable virtual therapist accessible 24/7. The development process may be controversial due to privacy concerns. But a coordinated effort to ensure anonymizing names and personal information before utilizing the data sets could present a viable solution.
So what could go wrong?
The common concerns that come to mind are related to the impact on jobs. In the short term, I believe the technology will bring an augmentation of human creativity and output rather than a replacement. But there's no doubt that those evolutions will cause some disruption to the world of work at some point in the future. As the solutions keep improving, employers will realize they can achieve equivalent results and serve the same number of customers with a much lower number of employees. For example, customer support departments will rely on a combination of virtual interactive agents and automatic responses to user requests. Humans would merely approve the replies and occasionally edit the content to correct glitches. Consequently, only a fraction of the workforce would be needed.
However, just as in the previous technological revolutions, the reduction of old jobs comes with the creation of new ones that didn't exist before. Two decades ago, Social Media Marketer, App Developer, Cloud Computing Specialist, YouTuber, Podcaster, Influencer, Video Game Streamer, AirBnB Host, Drone Operator, VR Designer, Smart Contract Developer, Growth Hacker, and Online Educator were professions that were not available. Likewise, we may be astonished by the new opportunities that arise from the present AI wave.
Beyond the impact on employment, the current LLMs do raise a few concerns. While they can be very broad and effective, as shown in the earlier examples, one worry is that they can capture undesirable biases which may be in the training data. Thus, they could amplify existing social prejudices as people use them.
Another cause of concern is that LLMs sometimes "make stuff up" that sounds real but is actually fake. For example, when I requested an essay about myself, I expected the model to return a few stitched paragraphs from my LinkedIn profile, assuming the professional social network public pages have been part of the training data.
Here’s what I received instead:

It is a wild piece of fiction of what my life could have been in a parallel universe.
The challenge with LLMs is they can be linguistically correct but factually incorrect. The reason goes back to how they are designed to work and how they are trained.

Christopher Manning gives a good analogy in his presentation of how LLMs are built. First, they play the Mad Libs Game and try to predict the next word within a particular context. The training occurs by reinforcing the rating of good guesses and downgrading the ones from wrong predictions. Once the model is trained, those final ratings, called weights, are used to make predictions of the most likely next word in the milieu of content the user provides. Subsequently, when LLMs lack input about a specific topic, they will still generate a combination of words that have a high probability of being pooled together from a language perspective, even if they represent fictitious facts.
InstructGPT is already an enhancement over the original GPT-3 at following user instructions and increasing truthfulness. So, I expect the subsequent iterations to keep improving by implementing extra validation layers and, ideally, not shying away from answering "I don't know" if necessary.
When it comes to the ugly side, 'The worst AI ever" by Alberto Romero covers the event of an LLM experiment leading to an obnoxious outcome. It depicts the case of a Machine Learning researcher that fine-tuned the training of an existing model on a toxic discussion forum and released it. Within two days, it was used by bots that generated over 30,000 posts of offensive and trolling content, mimicking the style of the chat board it was trained on.
Whereas the example above was intended for research purposes, a similar approach could occur within an ill-intentioned context.
Part II- Avoiding Concentration of Power: How Open Source, Crowdfunding and Distributed Computing Can Help Democratize AI
We have already had a taste of the side effects of the centralized power of social media giants over society, with the potential role of personalized targeting and algorithmic feeds in manipulating political campaigns, referendums, and public discourse. The latest AI developments could become a grander force than social media.
OpenAI's original ambition was to advance and responsibly democratize the AI field while avoiding that the power stays concentrated in a few giants' hands. It was initially structured as a non-profit with the promise to share the research and code. However, the evolution path branched in a different direction for reasons well described in the recent New York Times article. The founding team had to create a for-profit arm to finance the enormous resources required to build and run large-scale experiments. Along the way, Microsoft invested $1 Billion. Consequently, today most OpenAI breakthroughs are behind a closed wall, accessible through paid APIs. The exception is Whisper, the multi-language speech recognition and translation software recently open-sourced.
It's important to acknowledge that OpenAI API access to its models is already a form of democratization, even if it's based on a commercial service. It's what has enabled many of the innovative applications we have seen lately and will keep contributing to the field's evolution. The challenge is that the more people build on top of those proprietary backends, the more dependence and accumulation of power will centralize around a few players. In good times, it may not cause concerns. But in moments of economic misalignments or global conflicts, the risk exposure of dependent operations will be high. Those central entities could potentially pull the plug, instantly leaving businesses and critical processes of countries frozen. Thus, additional levels of democratization should be addressed.
Stability AI has opted for a different approach by open-sourcing Stable Diffusion. From a tweet by Emad Mostaque, it appears the intention is to keep opening up new developments as they are completed.
As we release faster and better and specific models expect the quality to continue to rise across the board.
— Emad (@EMostaque) August 23, 2022
Not just in image, audio next month, then we move onto 3D, video.
Language, code and more training right now…
Cutting edge AI that is open and inclusive 🙃 https://t.co/mlTfBeoJII
Other initiatives followed course like LAION, EleutherAI and Harmonai, open-sourcing research, data sets, and models for photos, language, and audio. Those are released under a Creative ML OpenRAIL-M license which allows commercial and non-commercial applications while focusing on ethical, legal, and responsible usage.
So there are encouraging enterprises currently in motion to ensure a more even and independent access to AI. What’s missing is the funding to cover the super computing resources required to allow the ongoing initiatives to build open source solutions at a scale on par with what the giant corporations can attain.
One way to address the capital challenge is through crowdfunding and distributed computing.
Crowdfunding
So far, Kickstarter has financed over 230,000 projects with more than $6 Billion. While Kickstarter focuses primarily on creative projects, other sites, such as experiment.com are designed for scientific research. Those services are great alternatives to fund exciting projects by allowing people to finance ideas they believe in. The rewards the backers receive can be anything from a personalized "thank you" note to early access to a finished product.
It is worth exploring funding experiments on the existing platforms to evaluate if they are suitable. Alternatively, the optimal way forward might be building a new crowdfunding platform specifically catering to foundation AI projects.
The Search for Extraterrestrial Intelligence (SETI)
SETI is a scientific quest to find evidence of intelligent life in the universe by analyzing the signals from radio telescopes.
You might wonder what aliens have to do with building large AI models.
In the late nineties, I downloaded a popular program called SETI@Home. It allowed your computer to participate in the search for extraterrestrial intelligence by donating idle CPU time to analyze pieces of the signals captured by the radio telescopes. It got activated instead of the screen saver and displayed fantastic visuals.
I ran the software for about two years, and even if my computer, or any other one, didn't discover green creatures from outer space, SETI@Home was the greatest distributed computing project in the world. The Berkeley SETI Research Center operated the program, and the initial ambition of the team was to get 50,000 to 100,000 contributors. Instead, since its launch in 1999, it has had over 5 million participants.
The training of large AI models could adopt a similar approach by crowdsourcing the processing capacity from distributed machines. For example, today's gaming rigs have highly capable GPUs that can be aggregated into a virtual supercomputer. Instead of directly providing cash via a crowdfunding campaign, people could contribute with their existing hardware and the required energy.
The engineering side is not as simple, though. Bandwidth for enormous data transfers is usually a constraint as most participants won't have home gigabit Internet speed. Furthermore, contributors may not keep their machines connected permanently. Thus, the approach requires an adaptation of the current methods.
"Deep Learning over the Internet: Training Language Models Collaboratively" by Max Ryabinin and Lucile Saulnier proposes a modified algorithm to address the limits of distributed training. It is vital to encourage similar developments until obtaining frameworks allowing to crowdsource any AI model training.
Crowdfunding and distributed computing can truly democratize access by providing the necessary resources to build large AI models outside the realm of heavily funded corporations. Those developments can then be open-sourced and freely available to everyone.
With more democratization also comes the dilemma of how to contain the potential adverse side effects.
At the basic level, courses about ethics and responsibility when building and releasing AI applications should be prioritized and strongly promoted. Raising people's awareness about the potential misuse consequences is a good place to start.
Another way is to develop guidelines, policies, and a certification system that the models must comply with to receive a safety label. This will prevent well-intended users from unknowingly downloading softwares that have built-in harmful behaviors.
Nevertheless, with such powerful systems, expecting a total containment of the potential harms would be naive. In the same way, the democratization of software compilers led to remarkable innovations but also allowed people to create computer viruses, we will have to deal with some problematic creations.
The computer virus case was initially solved by continuous improvements in anti-virus software. Later, the problem was eliminated by an evolution in operating systems architecture. Nowadays, no one has to worry about viruses in their iPhones or iPads.
So the solutions to the downsides of LLMs specifically, and AI generally, will most likely stay in a "work-in-progress mode" and evolve along the technological advances. It will be hard to fully "crack it" at the moment, but as long as the appropriate focus and funding are allocated to the challenge, I'm hopeful that the right balance could be reached at some point.
LLMs' possibilities are endless; the ability to automate and scale human communication and empathy with words can completely revolutionize fields like mental health and education via affordable, personalized 1-1 therapy or tutoring.
In the early Internet days, e-commerce and online newspapers were obvious, but Airbnb and Kickstarter were less predictable. With the arrival of mobiles and broadband, video calls were thought to be the killer app, but Uber and TikTok were difficult to foresee. Comparably, the most world-changing LLMs' use cases could be the ones we haven't thought about yet.
Democratizing access to AI is an important goal. It is already in motion with the emerging user friendly front end applications. But it is vital to push the democratization further through open-source projects, crowdfunding, distributed computing, and awareness programs. Companies, individuals, and even governments must work together to ensure that everybody benefits from the rewards without an overdependence on a few giant corporations. Doing so will create a brighter future for all.